The EEMUA 191 performance metrics have been adopted by many as their benchmark for a successful operator alarm system but realisation soon dawns that there are many ways to achieve the EEMUA metrics creating a strong suspicion that one must be ‘better’ in some way than all the others. Something more is needed. Achieving the EEMUA human factors/ergonomic metrics is only one of many requirements of a good operator alarm system.
The primary purpose of an operator alarm system is to request the operator to intervene and take action when process operation ceases to be ‘normal’. You might have expected that this would have led to more of a focus on the timeliness of alarms or on the elimination of false alarms or on understanding how alarm limits should relate to normal process operation but there just isn’t enough information in the alarm log to investigate such issues.
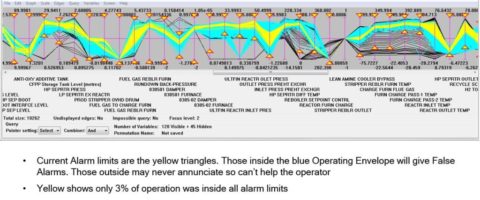
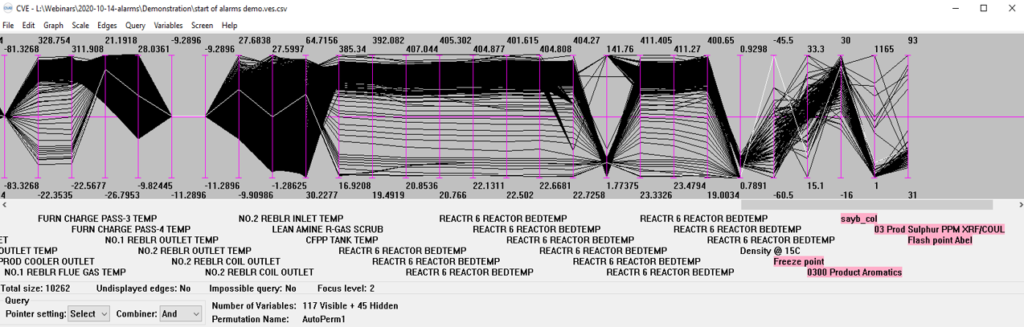
However, there is enough information in other databases commonly found in process plants and in particular in the process historian database (e.g. PI, PHD, IP21 and several others) where information on tens of thousands of process variables such as pressures, temperatures, flows and levels is available at intervals of a few seconds, often for many years of past operation. The problem has been in extracting understanding from such huge volumes of data. This changed with the availability of a graph showing a thousand or more variables in a single picture able to show, for the first time, the operating envelope from unit feed through to product rundown corresponding to any chosen definition of ‘normal’ for 1,000 or more process variables. On seeing the picture it becomes obvious to position alarm limits on or close to the boundary of the normal operating envelope. Alarm performance is easily calculated in terms of alarms annunciating and numbers of alarms awaiting the operator’s attention, had the new set of limits been in use during past operation. False alarms are largely eliminated, alarm timeliness often much improved and alarm performance is often dramatically improved when compared to existing alarm limits. Many consequential alarms can be seen, and even the size of past alarm floods will be reduced by setting alarm limits at the boundary of the operating envelope corresponding to the chosen definition of ‘normal operation’.
And it requires much less time than past ‘fix-today’s-bad-actors-first’ methods, whether you reset all the alarms at once in a single rationalization project or use the method over a period of time for ongoing alarm improvement. And when you have found the new limits, put them in the MAD for ongoing change management.
After implementation, process operators soon discover that the new alarms are much reduced in numbers and far more trustworthy. They will find themselves able to keep the process inside its operating envelope for more of the time, leading to increased achievement of the envelope’s operating objective and improved business effectiveness. Effectively, the new alarms will guide operations to achieve the operating objective using a smaller operating envelope. The alarm limits can then be moved inwards from time to time to follow the shrinking operating envelope boundary and continue the improvement. The best way to monitor and report alarm performance (and much more) is therefore to use the same 1,000 variable operating envelope graph when deviations due to process changes, ageing catalyst, different feed compositions and changing ambient conditions will be readily visible to all.
The 1,000 variable operating envelope graph is provided only by PPCL’s C Visual Explorer (CVE).